


AI Agents in VC: How to Automate the Investment Process, Starting with Data Rooms
Manually reviewing data rooms is outdated—AI agents do it better and faster

I will be kicking off a new series where I write about how to build AI agents to support investment processes. I will build these AI agents in parallel and improve them as we go along. This is a first take.

No big talk about how AI will change the VC industry and how LPs will be demanding AI strategies in the future. Let’s skip that and dive straight into a concrete use case: the data room review. Today, these large collections of documents are still manually reviewed, page by page.
The usual workflow: Get access, check for completeness, analyze all sorts of documents, discuss internally, and send endless Q&A rounds to the startup. This takes days and involves the entire deal team. But what if you could leverage AI agents to do this in hours if not minutes – with the same accuracy and speed?
This first post will walk you through building an AI agent step by step and mainly focusing on the principles that apply. Just like we moved from manual data entry to automated CRMs, AI agents are the next gold standard for VC funds. You already know that – that’s why you’re here. Let’s dive in. Simple explanations, no coding or technical background needed.
What are the key challenges in building an AI agent for data room reviews?
The challenge an AI agent must solve when reviewing a data room is handling large volumes of unstructured data efficiently. Data rooms often contain hundreds of documents in various formats – PDFs, Word files, Excel sheets, screenshots and presentations – each with different structures, languages, and complexities. The AI agent needs to quickly access, parse, and understand this data, identifying key information such as financial metrics, legal clauses and market data. It must also cross-reference documents, highlight inconsistencies, and flag missing information. Most importantly, the AI agent must provide clear, accurate summaries and insights that the VC team can trust, all while maintaining data security and adapting to different data room structures from deal to deal.
The tech stack should correspond to these challenges. The following principles should apply.
Accuracy: Extract and summarize information with minimal errors, ensuring reliable insights.
Speed: Process large document sets quickly to save time without compromising quality.
Context Awareness: Understand the VC’s needs, focusing on relevant details like financials, legal risks, and market data.
Transparency: Reference the exact source documents for each insight, allowing the deal team to verify critical points easily.
The following way we can resolve these principles is by including a simple tech stack.
Accuracy: Integrate the latest model to let your AI agent use cutting-edge models for precise data extraction and summarization.
Speed: Use parallel processing capabilities to review multiple documents at once, drastically reducing the time needed for data room reviews.
Context Awareness & Summarization: Implement a vector database to store document embeddings, allowing the AI agent to understand and maintain context across various documents and data points. AI agents can generate concise summaries of lengthy documents.
Transparency: Store document metadata in the vector database, enabling the AI agent to reference original documents for every insight it provides, ensuring easy verification and trust in the results.
Let’s build
We will build two AI agents. One will handle uploading hundreds of files to the vector database, while the other will answer questions based on the stored data. This architecture is flexible and can be adjusted to fit your needs.
Architecture
Document storage: Google Drive: Example data: Good Food Institute reports about alternative proteins. (This is still a blog about the Bioeconomy ;-) )
Automation and workflow management: n8n.io
Vector database for semantic search and retrieval: Pinecone. This is a specialized database that stores data as numerical vectors. It’s useful for “semantic search,” where the database finds information based on meaning, not just keywords.
AI Agent: OpenAI - model o4. Note that you can use any type of AI model here.
The first agent is structured as follows:

It’s a visual workflow showing how files from Google Drive are fetched, processed, and then stored as embeddings in Pinecone. Here’s the step‐by‐step flow as depicted:
Trigger: The flow starts when the user clicks “workflow.”
Google Drive (Search): The first Google Drive step is set up to locate files or folders in Drive (e.g., searching a directory).
Google Drive (Download): Once found, the files are passed to a second Google Drive step that downloads them.
Loop Over Items: Each downloaded file is fed into a loop, which processes the files one by one.
Default Data Loader + Recursive Text Splitter: Within the loop, a data loader reads each file, and a text splitter breaks the text into manageable chunks.
OpenAI Embeddings: Those text chunks are then sent to an OpenAI Embeddings step to generate vector embeddings.
Pinecone Vector Store: Finally, the embeddings are stored in Pinecone (a vector database) so they can be searched or queried later.
This setup helps populate your vector database and prepares you for data room reviews. Below is an example data room, which I populated with Good Food Institute reports that vary in size and content.

The vector database with the transformed files:

Now the second part of the AI agent is a RAG setup (Retrieval-Augmented Generation) also built with n8n. It integrates OpenAI’s Chat Model, Pinecone for vector storage, and a memory buffer to combine AI responses with external knowledge (in our case its the data room). Essentially, the AI system retrieves relevant documents from a database to generate answers that are more accurate and grounded in real data. This means it doesn’t rely on pre-trained data or web searches—it only generates answers based on the specific documents and data provided. This is exactly what we need when reviewing data rooms for target companies.
The second agent is structured as follows:

Trigger: "When chat message received": This initiates the workflow when a new message is received.
AI Agent (Tools Agent): The core processing unit that determines how to handle incoming queries. It integrates memory, chat models, and vector-based retrieval.
Memory: Window Buffer Memory: Stores the conversation history to provide context for better responses.
Chat Models: OpenAI Chat Model & OpenAI Chat Model1: These provide responses based on the chat history and retrieved information.
Vector Store: Pinecone Vector Store: Stores the embeddings generated with the first AI agent for efficient similarity searches.
Embeddings: OpenAI Embeddings: Converts text into vector embeddings for retrieval.
Answering Questions via a Vector Store: This module retrieves relevant information from Pinecone and combines it with the AI model’s response.
How the System Works Here:
A chat message is received.
The AI Agent determines if it can answer using memory or if it needs external knowledge.
If external knowledge is required:
The message is converted into an embedding using OpenAI Embeddings.
The system queries Pinecone (our data room) to find similar stored information.
The retrieved information is fed to the OpenAI Chat Model to generate a final response.
The response is sent back to the user.
This setup allows the AI agent to combine live AI responses with stored knowledge for better, more context-aware answers. It is ideal for handling queries where fast real-time knowledge retrieval is necessary (e.g., data room review, document-based Q&A, and investment research).
And that’s it—just like that. Simple magic. Now, let’s return to our data room and demonstrate how effectively it can answer our questions.
Three Examples
General questions:
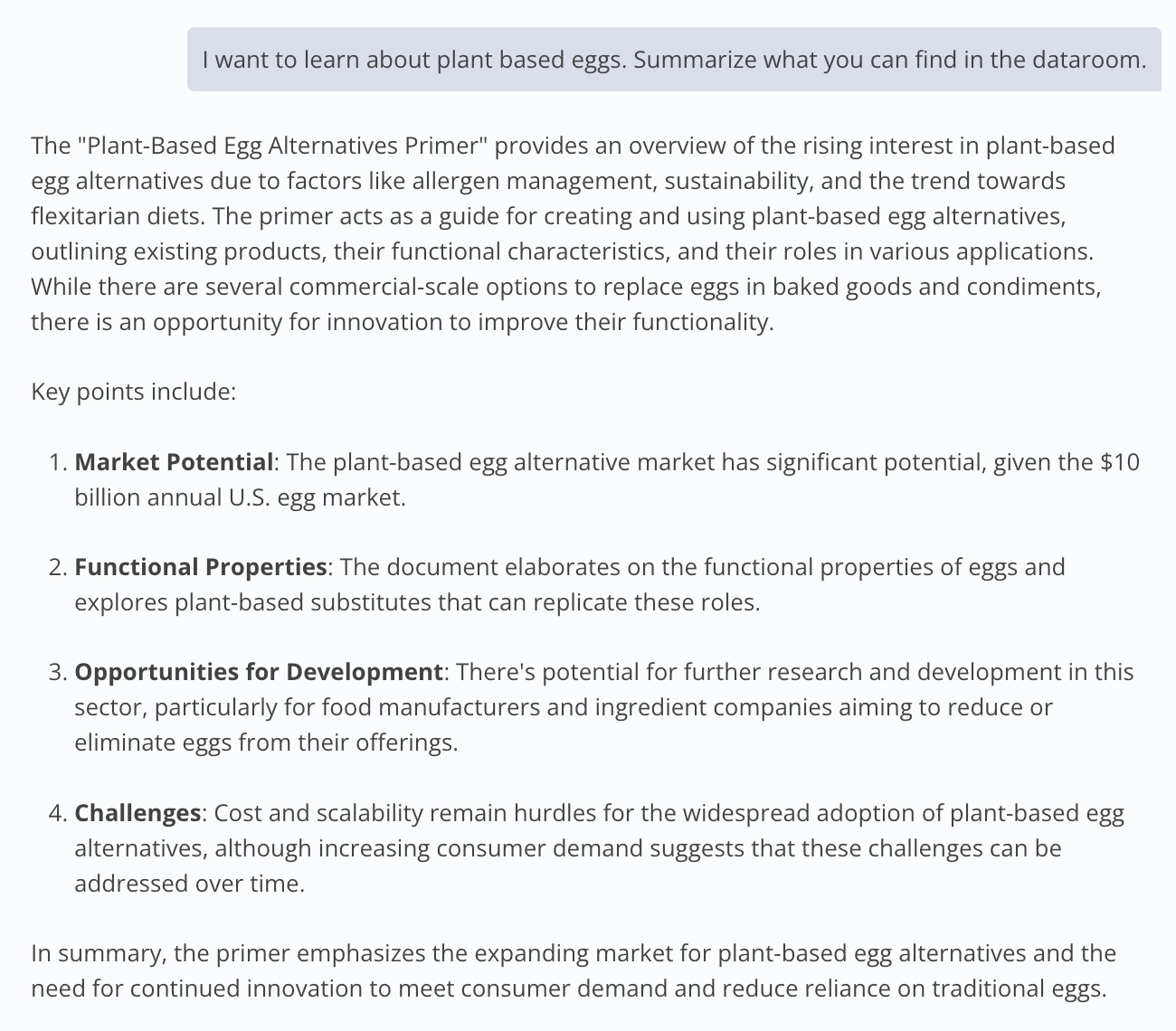
Prompt: I want to learn about plant based eggs. Summarize what you can find in the dataroom.
Specific questions:
Prompt: Tell me something about mung beans based on the protein primer.
Original Source:

Outcome:

Document review and Q&A:
Prompt: Please review the document: Cell line development and utilisation trends in the cultivated meat industry. I would like to understand what are open questions that I could ask an expert that are not yet covered by the document.

Wrapping up, this is a first take, but there’s more to improve. Some ideas to play around with:
Expand access. Don’t limit the Agent to a single data room. Provide access to all your internal documents and reports. This ensures a deeper knowledge base and more accurate insights.
Compare notes. Include your personal notes. Let the Agent cross-check them with findings from previous data rooms. This can reveal patterns and highlight any inconsistencies.
Use standardized templates. Create a structured Q&A format. Send this template directly to the startup for a quick, consistent overview. It saves time and keeps everything organized.
Add a data room system. Make it easy to upload and update documents. Keep everything in one accessible, secure location.
Add memory. Enable the system to store key information and data room findings (e.g. market size data) in a memory database, making it easily accessible without the need for manual note-taking.
Follow along as we explore how to leverage AI agents for your fund, integrate AI with existing VC tools, automate investment processes, and more. If you want to build this for your fund, reach out—I’m happy to help set it up and answer any questions, especially on how to integrate it seamlessly into your workflows.
Thanks for reading. Reach me with tips, questions, and feedback on Twitter or LinkedIn.
If you enjoy this newsletter, why not share it with your friends and co-workers?
The views expressed here are my own. All information contained in here has been obtained from publicly available information. While taken from sources believed to be reliable I have not independently verified such information and make no representations about the enduring accuracy of the information or its appropriateness for a given situation. This content is provided for informational purposes only, and should not be relied upon as legal, business, investment, or tax advice. Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. For questions simply reply to this email.
Thanks for sharing this detailed application example👍🏻